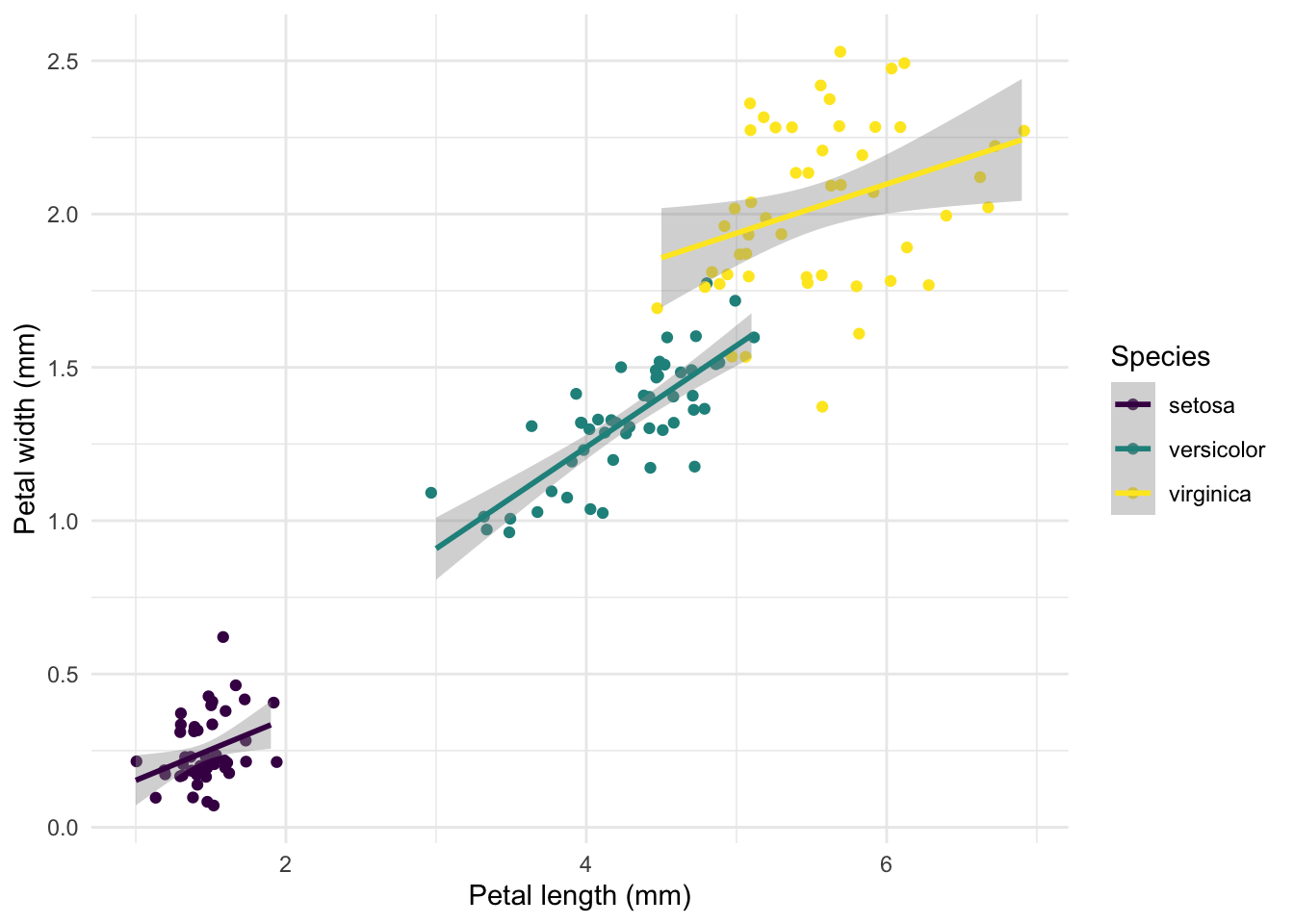
Le bloc de code ci-dessous combine tous les aspects que nous allons aborder dans ce document : utilisation de packages, du pipe %>%, préparation de données issues d’un tableau, production et customisation d’un graphe, création d’une fonction, calculs combinés sur listes de données, etc.
Comme pour tous les langages, naturels ou informatiques, vous parviendrez à déchiffrer avant d’écrire. D’autant que R est plus intransigeant qu’un autochtone en terre étrangère et ne laissera pas passer d’approximation.
Ceci étant, même si vous n’avez jamais vu de code R en action, ces commandes ainsi que les commentaires, précédés d’un # devraient être raisonnablement compréhensibles. Admirez la beauté du R “moderne”!
# dependencieslibrary(tidyverse)# data tidying# we will use the famous iris datasetiris2 <- iris %>%as_tibble() %>%# only keep columns of interestselect(pl=Petal.Length, pw=Petal.Width, sp=Species)# let's print in on the consoleiris2
# a quick graph using ggplot2# initialize using our datasetggplot(iris2) +# define axes and columns to displayaes(pl, pw, col=sp) +# draw points, slightly jittered to show all 150 pointsgeom_jitter() +# let's add a linear model smoothgeom_smooth(method="lm", formula="y~x") +# here we tune coloursscale_color_viridis_d() +# and add more cosmeticsguides(colour=guide_legend("Species")) +xlab("Petal length (mm)") +ylab("Petal width (mm)") +# we love both cosmetics and minimal designtheme_minimal()
# a little helper function to calculate a lm and extract the adjusted R2 from itlm_adj_r2 <-function(x) summary(lm(pl~pw, data=x))$adj.r.squared# let's adjust 3 linear models and extract adj R2# group-wise statisticsiris2 %>%nest(data=c(pl, pw)) %>%mutate(adj_r2=map_dbl(data, lm_adj_r2))